Back
Valuing research works by eliciting comparisons from EA researchers
webAuthor
NunoSempere
Credibility Rating
3/5
Good(3)Good quality. Reputable source with community review or editorial standards, but less rigorous than peer-reviewed venues.
Rating inherited from publication venue: EA Forum
Relevant to anyone thinking about how to measure or prioritize AI safety research impact; offers a community-based comparative valuation method that could complement other research evaluation frameworks.
Metadata
Importance: 42/100analysis
Summary
This post describes a methodology for estimating the value of research outputs by asking EA researchers to make pairwise or relative comparisons between works, then aggregating those judgments into a quantitative value scale. The approach aims to help prioritize and allocate resources toward the most impactful research in the effective altruism and AI safety ecosystem.
Key Points
- •Proposes using expert elicitation of comparative judgments to assign relative value scores to research works
- •Aggregates pairwise comparisons from EA researchers into a consistent value scale for research prioritization
- •Addresses the challenge of quantifying research impact in domains where direct outcome measurement is difficult
- •Could inform funding decisions, researcher prioritization, and evaluation of AI safety and EA research outputs
- •Represents an empirical approach to research evaluation grounded in community expert opinion rather than citation metrics
Cached Content Preview
HTTP 200Fetched Apr 10, 202619 KB
# Valuing research works by eliciting comparisons from EA researchers
By NunoSempere
Published: 2022-03-17
**tl;dr:** 6 EA researchers each spent ~1-2 hours estimating the value (relative counterfactual values) of 15 very different research documents. The results varied highly between researchers and within similar comparisons differently posed to the same researchers. This variance suggests that EAs might have relatively undeveloped assessments of the value of different projects.
**Executive Summary**
---------------------
Six EA researchers I hold in high regard—Fin Moorhouse, Gavin Leech, Jaime Sevilla, Linch Zhang, Misha Yagudin, and Ozzie Gooen—each spent 1-2 hours rating the value of different pieces of research. They did this rating using a [utility function extractor](https://utility-function-extractor.quantifieduncertainty.org/research), an app that [presents the user with pairwise comparisons](https://forum.effectivealtruism.org/posts/9hQFfmbEiAoodstDA/simple-comparison-polling-to-create-utility-functions) and aggregates these comparisons to produce a utility function.
This method revealed a wide gap between different researchers' conceptions of research value. Sometimes, their disagreement ranged over several orders of magnitude. Results were also inconsistent at the individual level: a test subject might find A to be x times as valuable as B, and B to be y times as valuable as C, but A to be something very different from x*y times as valuable as C.
It seems clear that individual estimates, even those of respected researchers, are likely very noisy and often inaccurate. Future research will further investigate ways to better elicit information from these people and recommend best guesses for the all-things-considered answers. It is also likely that researchers spending more time would have produced better estimates, and we could also experiment with this in the future.
My guess is that EA funders also have inconsistent preferences and similarly wide-ranging disagreements. That is one of the reasons I am excited about augmenting or partially automating them.
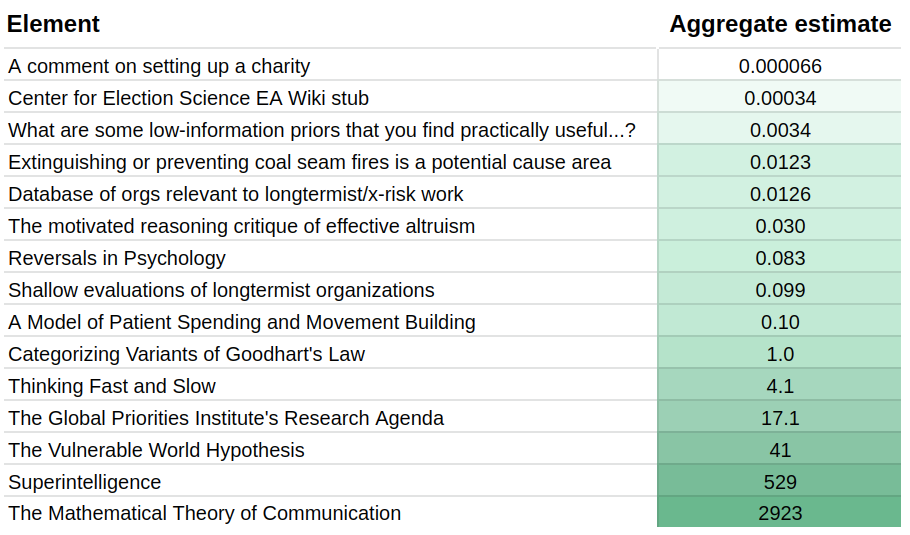
Current aggregate estimates look as follows:
**Motivation**
--------------
EAs make important decisions based on how valuable different projects seem. For example, EAs can distribute funding based on expectations of future value. In fact, I estimate that the group I studied will cumulatively grant several millions of dollars, both in terms of advising various funds and because they are influential in the longtermist funding space.
Estimating the value of past projects seems easier than estimating the value of future projects, but even that is relatively tricky. We at the Quantified Uncertainty Research Institute are interested in helping to encourage more estimation of previous and future projects, and we are trying to find the best ways of doing so.
The most
... (truncated, 19 KB total)Resource ID:
ab2d4c8f2bf8a0a7 | Stable ID: sid_s8Eq86tRnk