Research Update: Algorithmic vs. Holistic Evaluation - METR
webCredibility Rating
4/5
High(4)High quality. Established institution or organization with editorial oversight and accountability.
Rating inherited from publication venue: METR
Metadata
Cited by 1 page
| Page | Type | Quality |
|---|---|---|
| Sandboxing / Containment | Approach | 91.0 |
Cached Content Preview
HTTP 200Fetched Apr 30, 202645 KB
[](https://metr.org/)
- [Research](https://metr.org/research)
- [Notes](https://metr.org/notes)
- [Updates](https://metr.org/blog)
- [About](https://metr.org/about)
- [Donate](https://metr.org/donate)
- [Careers](https://metr.org/careers)
Menu
## TL;DR
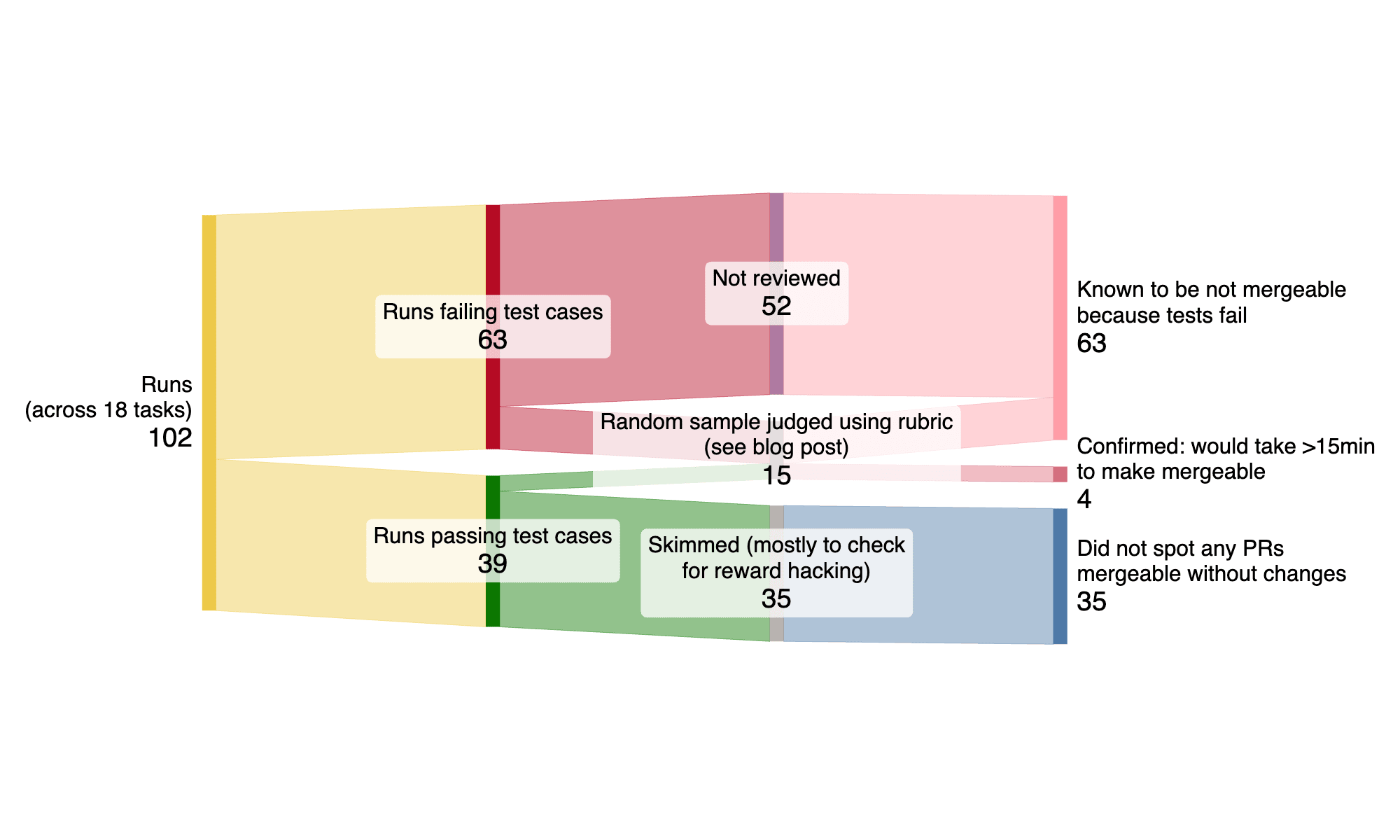
- On 18 real tasks from two large open-source repositories, early-2025 AI agents often implement functionally correct code that cannot be easily used as-is, because of issues with test coverage, formatting/linting, or general code quality.
- This suggests that automatic scoring used by many benchmarks\[1\][1](https://metr.org/blog/2025-08-12-research-update-towards-reconciling-slowdown-with-time-horizons/#fn:1) may overestimate AI agent real-world performance.
## Background
Many AI benchmarks use algorithmic scoring\[2\][2](https://metr.org/blog/2025-08-12-research-update-towards-reconciling-slowdown-with-time-horizons/#fn:2) to evaluate how well AI systems perform on some set of tasks. For example, the popular benchmark SWE-Bench Verified measures whether an AI system passes test cases implemented in code by the original human PR authors. Algorithmic scoring makes it easy to evaluate a new system on the benchmark, because the tests are re-usable, run quickly, and do not require human intervention/manual review.
However, many goals are difficult to represent with algorithmic scoring functions. For example, judging the quality of documentation is difficult to do automatically—you can’t (easily) write test cases that evaluate this, because documentation is typically unstructured natural language.
Particularly given the recent popularity of methods like reinforcement learning with verifiable rewards, which relies on algorithmic scoring functions, we might expect that AI systems will perform better on tasks that can be automatically evaluated compared to ones that can’t.
If AIs are much more capable on tasks that can be automatically evaluated, we might overestimate how useful they are in the field, because we often task AI systems with work that can’t be automatically evaluated. We hypothesize that this contributes to the apparent gap between our measured [time horizon](https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/) of Claude 3.7 Sonnet of about one hour, and the slowdown effect we observe from our recent [developer productivity RCT](https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/) (which includes many tasks that take humans an hour to complete).
## Methodology
At a high level, we evaluate autonomous agent performance when attempting to complete open-source software tasks. We compare their performance as evaluated by two methods: automatic/algorithmic scoring (using test cases implemented by the original PR authors), and manual/rubric review.
### Tasks and Development Environme
... (truncated, 45 KB total)Resource ID:
d7c0a3d20e24f049 | Stable ID: sid_l8c7HDS5Bw