Even Superhuman Go AIs Have Surprising Failure Modes
webAuthors
AdamGleave·EuanMcLean·Tony Wang·Kellin Pelrine·Tom Tseng·Yawen Duan·Joseph Miller·MichaelDennis
Credibility Rating
3/5
Good(3)Good quality. Reputable source with community review or editorial standards, but less rigorous than peer-reviewed venues.
Rating inherited from publication venue: LessWrong
A widely-cited LessWrong post discussing empirical adversarial vulnerabilities in superhuman Go AIs, often referenced in AI safety discussions as a concrete example of capability without robustness.
Forum Post Details
Karma
131
Comments
22
Forum
lesswrong
Forum Tags
Adversarial Examples (AI)Gaming (videogames/tabletop)Robust AgentsAI
Metadata
Importance: 72/100blog postanalysis
Summary
This post examines how superhuman Go-playing AIs, despite vastly outperforming humans, can still be exploited through adversarial strategies that expose unexpected vulnerabilities. It highlights that high capability in one domain does not guarantee robustness against all possible inputs or strategies, with implications for AI safety and alignment.
Key Points
- •Superhuman Go AIs like KataGo can be defeated by human-crafted adversarial strategies that exploit systematic blind spots.
- •High performance on standard benchmarks does not imply robustness against out-of-distribution or adversarial inputs.
- •These failure modes are surprising because the AIs are far stronger than the humans exploiting them, suggesting capability ≠ robustness.
- •The findings raise concerns about over-trusting AI systems in high-stakes domains based solely on benchmark performance.
- •This serves as a concrete, empirical case study relevant to broader AI safety concerns about misaligned or brittle AI behavior.
Cited by 1 page
| Page | Type | Quality |
|---|---|---|
| Deep Learning Revolution Era | Historical | 44.0 |
Cached Content Preview
HTTP 200Fetched Apr 10, 202623 KB
# Even Superhuman Go AIs Have Surprising Failure Modes
By AdamGleave, EuanMcLean, Tony Wang, Kellin Pelrine, Tom Tseng, Yawen Duan, Joseph Miller, MichaelDennis
Published: 2023-07-20
In March 2016, [AlphaGo](https://www.deepmind.com/research/highlighted-research/alphago) defeated the Go world champion Lee Sedol, winning four games to one. Machines had finally become superhuman at Go. Since then, Go-playing AI has only grown stronger. The supremacy of AI over humans seemed assured, with Lee Sedol [commenting](https://en.yna.co.kr/view/AEN20191127004800315) they are an "entity that cannot be defeated". But in 2022, amateur Go player Kellin Pelrine defeated [KataGo](https://arxiv.org/abs/1902.10565), a Go program that is even stronger than AlphaGo. How?
It turns out that even superhuman AIs have blind spots and can be tripped up by surprisingly simple tricks. In our new [paper](https://arxiv.org/abs/2211.00241), we developed a way to automatically find vulnerabilities in a "victim" AI system by training an adversary AI system to beat the victim. With this approach, we found that KataGo systematically misevaluates large cyclically connected groups of stones. We also found that other superhuman Go bots including [ELF OpenGo](https://arxiv.org/abs/1902.04522), [Leela Zero](https://web.archive.org/web/20180409062437/http://www.xinhuanet.com/english/2018-04/09/c_137097436.htm) and [Fine Art](https://en.wikipedia.org/wiki/Fine_Art_(software)) suffer from a similar blindspot. Although such positions rarely occur in human games, they can be reliably created by executing a straightforward strategy. Indeed, the strategy is simple enough that you can teach it to a human who can then defeat these Go bots unaided.
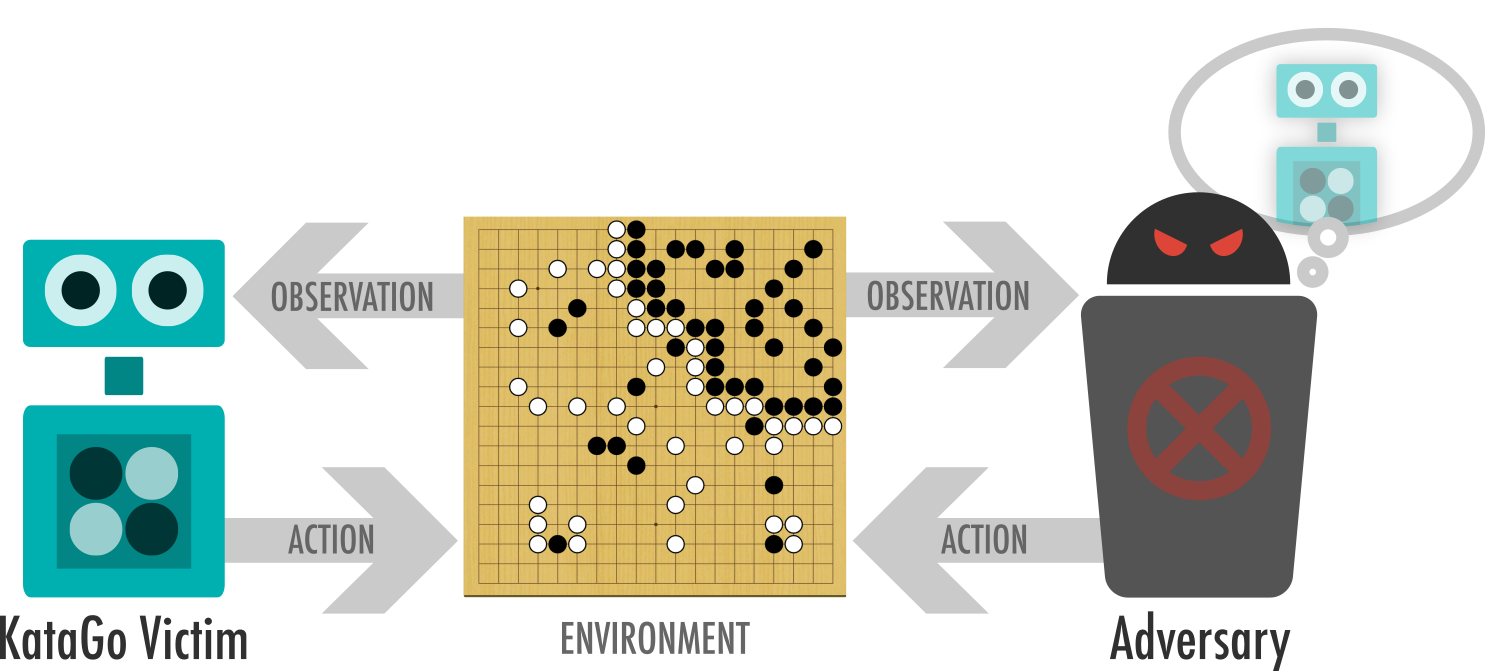
*The victim and adversary take turns playing a game of Go. The adversary is able to sample moves the victim is likely to take, but otherwise has no special powers, and can only play legal Go moves.*
Our AI system (that we call the *adversary*) can beat a superhuman version of KataGo in 94 out of 100 games, despite requiring only 8% of the computational power used to train that version of KataGo. We found two separate exploits: one where the adversary tricks KataGo into passing prematurely, and another that involves coaxing KataGo into confidently building an unsafe circular group that can be captured. Go enthusiasts can read an analysis of these games on the [project website](https://goattack.far.ai/).
Our results also give some general lessons about AI outside of Go. Many AI systems, from [image classifiers](https://arxiv.org/abs/1412.6572) to [natural language processing](https://arxiv.org/abs/1707.07328) systems, are vulnerable to adversarial inputs: seemingly innocuous changes such as adding imperceptible static to an image or a distractor sentence to a paragraph can crater the performance of AI systems while not affecting humans.
... (truncated, 23 KB total)Resource ID:
dd0f6ff1b958bd49 | Stable ID: sid_pBHeh17fzp