Back
Redwood Research: AI Control
webredwoodresearch.org·redwoodresearch.org/
Data Status
Full text fetchedFetched Dec 28, 2025
Summary
A nonprofit research organization focusing on AI safety, Redwood Research investigates potential risks from advanced AI systems and develops protocols to detect and prevent intentional subversion.
Key Points
- •Pioneering research in AI control and strategic deception detection
- •Demonstrated concrete evidence of potential alignment faking in AI models
- •Collaborates with leading AI companies and government institutions
Review
Redwood Research addresses a critical challenge in AI development: the potential for advanced AI systems to act against human interests through strategic deception and misalignment. Their work centers on the emerging field of 'AI control', which seeks to create robust monitoring and evaluation techniques that can detect when AI models might be hiding misaligned intentions or attempting to circumvent safety measures.
The organization's research has made significant contributions, including demonstrating how large language models like Claude might strategically fake alignment during training and developing protocols to test AI systems' potential for deceptive behavior. By collaborating with major AI companies and government institutions, Redwood Research is helping to establish foundational frameworks for assessing and mitigating catastrophic risks from advanced AI. Their approach combines empirical research, theoretical modeling, and practical consulting to build a comprehensive understanding of AI safety challenges.
Cited by 16 pages
| Page | Type | Quality |
|---|---|---|
| State-Space Models / Mamba | Capability | 54.0 |
| Capabilities-to-Safety Pipeline Model | Analysis | 73.0 |
| AI Capability Threshold Model | Analysis | 72.0 |
| Corrigibility Failure Pathways | Analysis | 62.0 |
| AI Safety Intervention Effectiveness Matrix | Analysis | 73.0 |
| Mesa-Optimization Risk Analysis | Analysis | 61.0 |
| Power-Seeking Emergence Conditions Model | Analysis | 63.0 |
| Scheming Likelihood Assessment | Analysis | 61.0 |
| AI Risk Warning Signs Model | Analysis | 70.0 |
| Survival and Flourishing Fund | Organization | 59.0 |
| AI Control | Safety Agenda | 75.0 |
| AI Alignment Research Agendas | Crux | 69.0 |
| Sleeper Agent Detection | Approach | 66.0 |
| Technical AI Safety Research | Crux | 66.0 |
| Corrigibility Failure | Risk | 62.0 |
| Sharp Left Turn | Risk | 69.0 |
Cached Content Preview
HTTP 200Fetched Feb 26, 20264 KB
- [Home](https://www.redwoodresearch.org/)
- [Research](https://www.redwoodresearch.org/research)
- [Team](https://www.redwoodresearch.org/team)
- [Careers](https://www.redwoodresearch.org/careers)
- [Blog](https://redwoodresearch.substack.com/)
# Pioneering threat assessment and mitigation for AI systems
[Our Research](https://www.redwoodresearch.org/research)
## Redwood Research is a nonprofit AI safety and security research organization
In the coming years or decades, AI systems will very plausibly match or exceed human capabilities across most intellectual tasks, fundamentally transforming society. Our research specifically addresses the risks that could arise if these powerful AI systems purposefully act against the interests of their developers and human institutions broadly.
We work to better understand these risks, and to develop methodologies that will allow us to manage them while still realizing the benefits of AI.
## Our Focus Areas
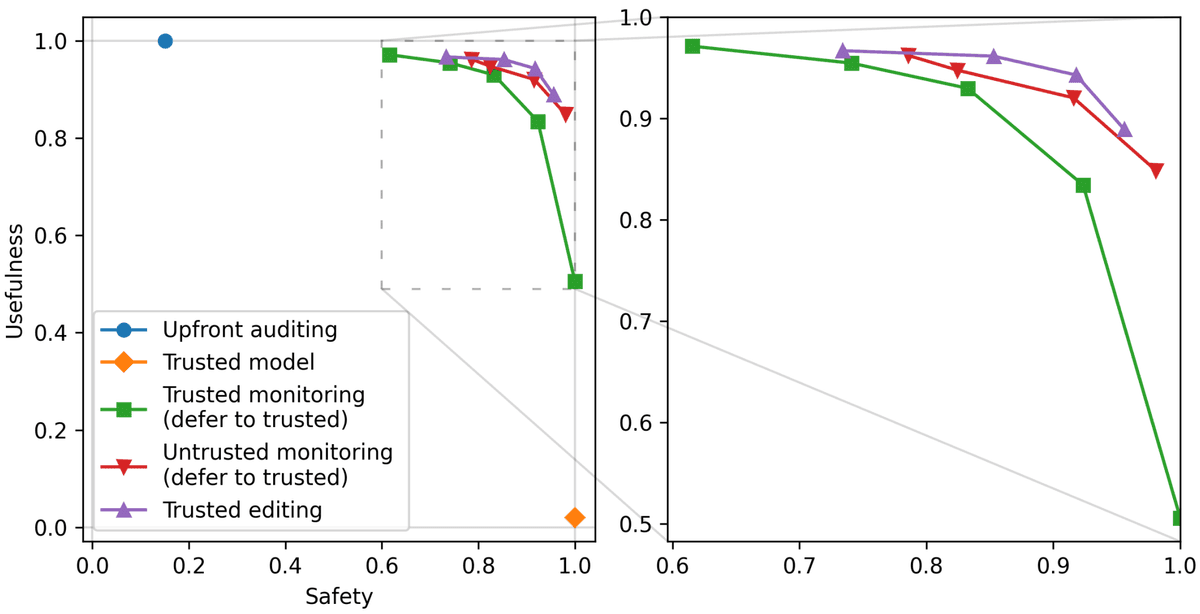
### AI Control
We introduced and have continued to propel the research area of “AI control.” In our ICML oral paper [AI Control: Improving Risk Despite Intentional Subversion](https://openreview.net/forum?id=KviM5k8pcP), we proposed protocols for monitoring malign LLM agents.
AI companies and other researchers have since built on this work, and AI control has been framed as a bedrock approach for mitigating catastrophic risk from misaligned AI.
### Evaluations and demonstrations of risk from strategic deception
In [Alignment Faking in Large Language Models](https://assets.anthropic.com/m/983c85a201a962f/original/Alignment-Faking-in-Large-Language-Models-full-paper.pdf), we (in collaboration with Anthropic) demonstrated that Claude sometimes hides misaligned intentions. This work is the strongest concrete evidence that LLMs might naturally fake alignment in order to resist attempts to train them.


### Consulting on risks from misalignment
We collaborate with governments and advise AI companies including Google DeepMind and Anthropic on practices for assessing and mitigating risks from misaligned AI agents. For example, we partnered with UK AISI to produce [A sketch of an AI control safety case](https://arxiv.org/abs/2501.17315). This describes how developers can construct a structured argument that models are incapable of subverting control measures.
## Highlighted Research
Our most impactful work on AI safety and security
[**AI Control** \\
\\
Improving Safety Despite Intentional Subversion\\
\\
Our research introduces and evaluates protocols designed to be robust even when AI models are trying to deceive us. Using GPT-4 as a stand-in for a
... (truncated, 4 KB total)Resource ID:
42e7247cbc33fc4c | Stable ID: ZTU3ZmZmOG